











Cassie-Kay McQuinn was selected as the recipient of the Stanger Endowed Graduate Fellowship. Established by Dianna Stanger, the fellowship provides academic freedom to selected fellows by providing a portion of their support for two years. The goal of the fellowship is to give students the confidence they need to pursue their dreams regardless of the obstacles that are in their way. The selection process for the fellowship focuses on how the student plans to leverage their Ph.D. toward the greater good and on ways in which the student has shown commitment to advancing women’s participation and inclusion in Aerospace Engineering and other STEM fields.
Cassie-Kay was an active member of Club of Females in Engineering (CAFE) throughout her undergraduate studies. This organization highlights the importance of academic excellence, career development, and providing a community for women studying engineering. As a graduate student she has been actively involved in student mentorship through the VSCL and Sigma Gamma Tau (SGT), where she served as the president in 2022. Cassie-Kay wants to leverage her skill set and experience to bring technology and therefore encouragement to people and students who do not have access to resources or the support to pursue a STEM career.







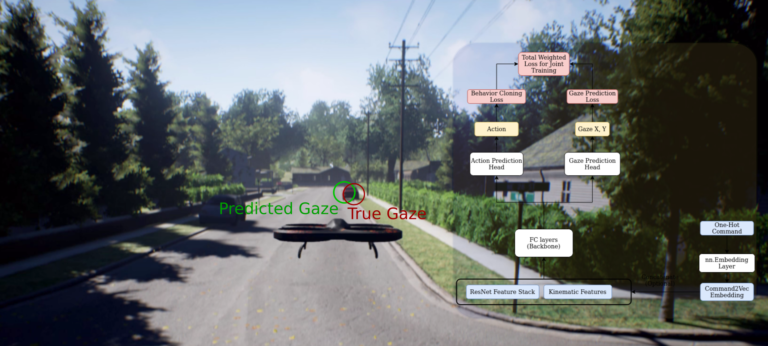
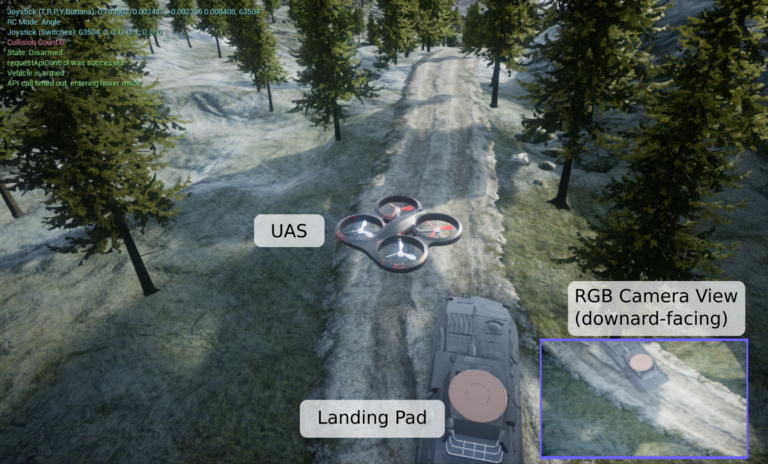
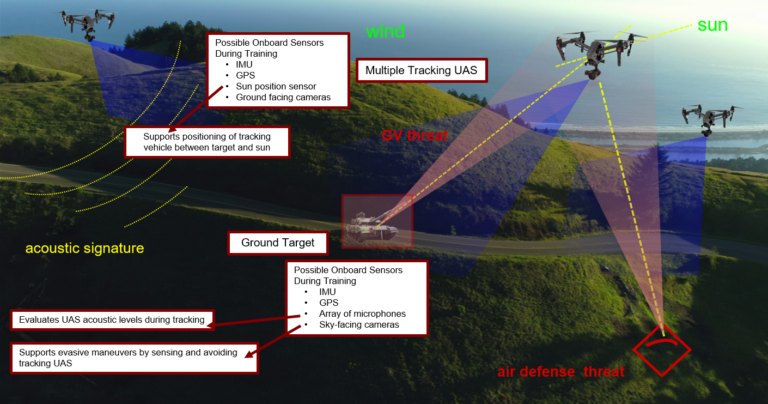
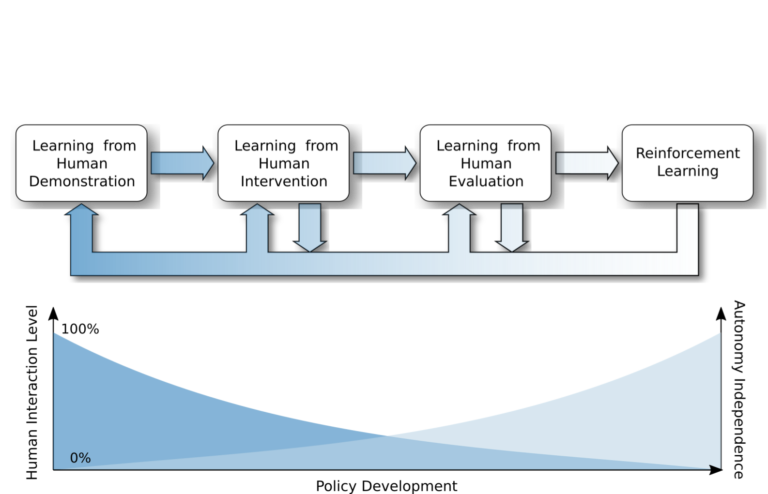
 Approaches for teaching learning agents via human demonstrations have been widely studied and successfully applied to multiple domains. However, the majority of imitation learning work utilizes only behavioral information from the demonstrator, i.e. which actions were taken, and ignores other useful information. In particular, eye gaze information can give valuable insight towards where the demonstrator is allocating visual attention, and holds the potential to improve agent performance and generalization. In this work, we propose Gaze Regularized Imitation Learning (GRIL), a novel context-aware, imitation learning architecture that learns concurrently from both human demonstrations and eye gaze to solve tasks where visual attention provides important context. We apply GRIL to a visual navigation task, in which an unmanned quadrotor is trained to search for and navigate to a target vehicle in a photo-realistic simulated environment. We show that GRIL outperforms several state-of-the-art gaze-based imitation learning algorithms, simultaneously learns to predict human visual attention, and generalizes to scenarios not present in the training data.
Approaches for teaching learning agents via human demonstrations have been widely studied and successfully applied to multiple domains. However, the majority of imitation learning work utilizes only behavioral information from the demonstrator, i.e. which actions were taken, and ignores other useful information. In particular, eye gaze information can give valuable insight towards where the demonstrator is allocating visual attention, and holds the potential to improve agent performance and generalization. In this work, we propose Gaze Regularized Imitation Learning (GRIL), a novel context-aware, imitation learning architecture that learns concurrently from both human demonstrations and eye gaze to solve tasks where visual attention provides important context. We apply GRIL to a visual navigation task, in which an unmanned quadrotor is trained to search for and navigate to a target vehicle in a photo-realistic simulated environment. We show that GRIL outperforms several state-of-the-art gaze-based imitation learning algorithms, simultaneously learns to predict human visual attention, and generalizes to scenarios not present in the training data. selected by the AERO Graduate Program Committee with an award of $1,000.
selected by the AERO Graduate Program Committee with an award of $1,000.






