Army Research Laboratory
9 August 2019 – 8 August 2024
Total award $1,250,000
Current state-of-the-art research on learning algorithms focuses on end-to-end approaches. The learning agent is initialized with no previous knowledge of the task nor the environment and the action selection process (trial-and-error) develops almost randomly. To efficiently and safely train autonomous systems in real-time, the Cycle-of-Learning (CoL) for Autonomous Systems combines supervised and reinforcement learning theories with human input modalities. This approach was shown to improve task performance while requiring fewer interactions with the environment. The research in this project directly supports the essential Human-Agent Teaming research by enabling efficient training of autonomous systems through novel forms of human interaction.
This project investigates if it is possible to train a learning agent to learn a latent space initially from human interaction and perform tasks entirely in these latent space worlds before interacting with the hardware. This approach has benefits for real-world robotic application where safety is critical and interactions with the environment are expensive.
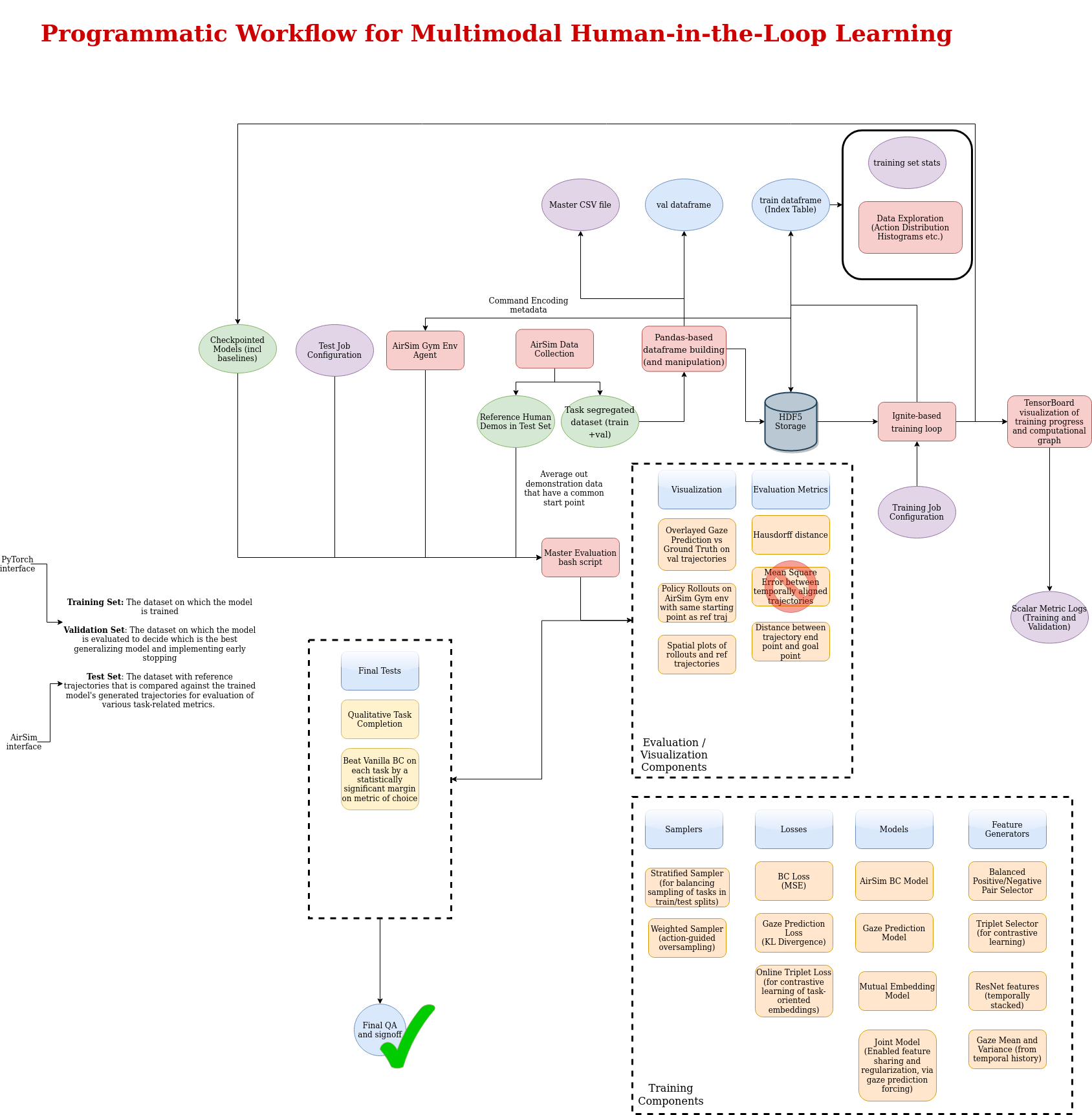
The objectives of this research are:
- Extending previous CoL work by developing a model-based reinforcement learning algorithm that learns the environment dynamics from human interaction and on-policy data.
- Demonstrating in hardware the current stage of the CoL, specifically in a human and small Unmanned Air System (human-sUAS) scenario.
- Extending the Cycle-of-Learning to a multi-agent setting to accommodate a mixed squad of multiple humans and sUAS.
The hardware implementation aims to replicate using a real vehicle the CoL results that have been observed using the simulated environment Microsoft AirSim for the quadrotor landing task. This hardware demonstration includes investigation of computational limitation, sensor and platform disparities, dynamic range limits, and vehicle dynamics on the CoL. Alternative approaches for the perceptual front-end extraction will be investigated, as well as methodologies for human intervention and possible autonomous Return to Launch (RTL). Results in hardware in terms of task performance and sample efficiency will be compared with already proven results achieved in the Microsoft AirSim simulated environment.
The third area will involve extending the Cycle-of-Learning to a multi-agent domain to solve tasks that require coordination with multiple sUAS and human teammates.
The result of this project will be algorithms and models that enable novel forms of human and AI integration to enable fast and efficient training of autonomous systems. Additionally, software and hardware infrastructure to allow the deployment of those algorithms and models on physical quadrotor systems. Research efforts on ways to improve these algorithms will be done through collaboration with ARL technical representatives with expertise in human-in-the-loop reinforcement learning and machine learning.
Working with me on this project are:
Graduate Students:
-Ritwik Bera, Ph.D. AERO
-Ravi Thakur, Ph.D. AERO