Army Research Laboratory
Co-Principal Investigator
9 August 2019 – 8 August 2024
This work investigates how to efficiently transition and update policies, trained initially with demonstrations, using off-policy actor-critic reinforcement learning. In this work we propose the Cycle-of-Learning (CoL) framework that uses an actor-critic architecture with a loss function that combines behavior cloning and 1-step Q-learning losses with an off-policy pre-training step from human demonstrations. This enables transition from behavior cloning to reinforcement learning without performance degradation and improves reinforcement learning in terms of overall performance and training time. Additionally, we carefully study the composition of these combined losses and their impact on overall policy learning and show that our approach outperforms state-of-the-art techniques for combining behavior cloning and reinforcement learning for both dense and sparse reward scenarios.
The Cycle-of-Learning (CoL) framework is a method for transitioning behavior cloning (BC) policies to reinforcement learning (RL) by utilizing an actor-critic architecture with a combined BC+RL loss function and pre-training phase for continuous state-action spaces, in dense- and sparse-reward environments. This combined BC+RL loss function consists of the following components: an expert behavior cloning loss that bounds actor’s action to previous human trajectories, 1-step return Q-learning loss to propagate values of human trajectories to previous states, the actor loss, and a L2 regularization loss on the actor and critic to stabilize performance and prevent over-fitting during training. The implementation of each loss component can be seen in our paper.
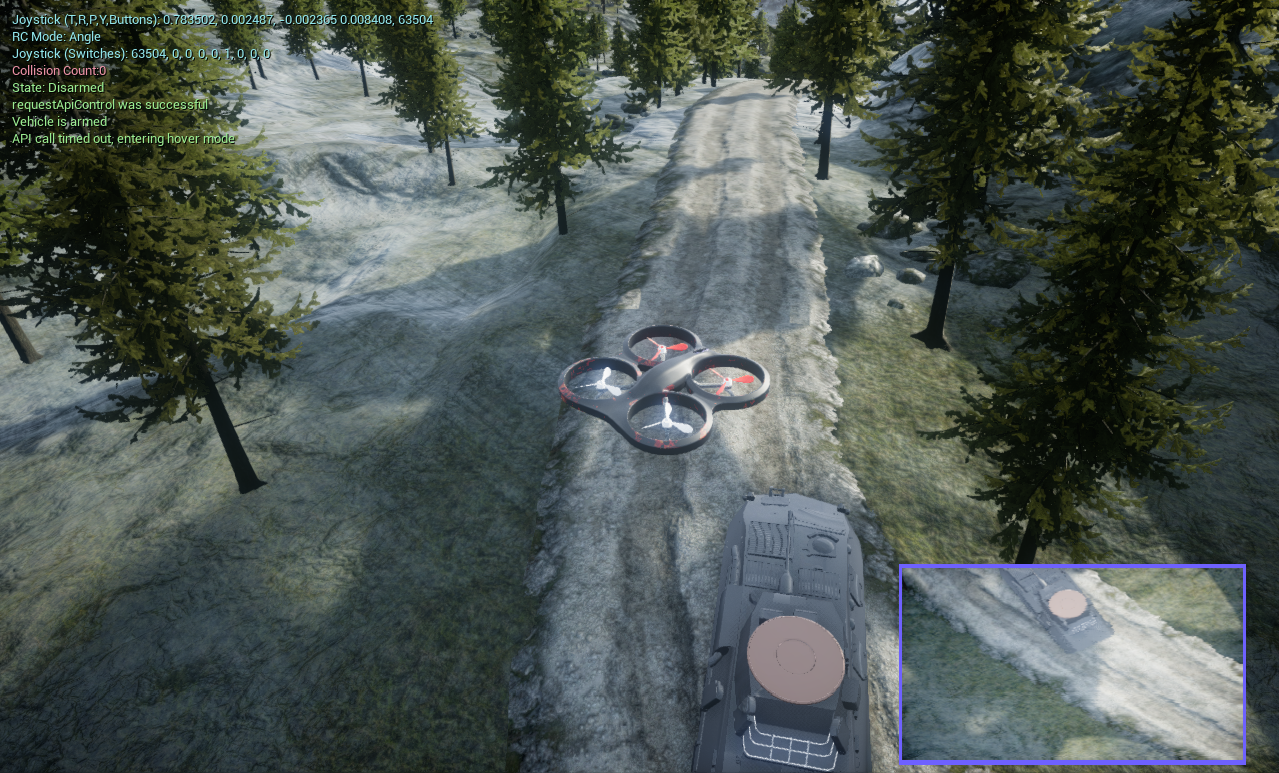
Our approach starts by collecting contiguous trajectories from expert policies (in this case, humans) and stores the current and subsequent state-actions pairs, reward received, and task completion signal in a permanent expert memory buffer. We validate our approach in three environments with continuous observation- and action-space: LunarLanderContinuous-v2 (dense and sparse reward cases) and a custom quadrotor landing task with wind disturbance implemented using Microsoft AirSim.
The paper documenting this work, “Integrating Behavior Cloning and Reinforcement Learning for Improved Performance in Dense and Sparse Reward Environments,” is available at the official AAMAS 2020 proceedings, together with the supplemental material detailing the training hyperparameters. A summary video of the proposed method can be found here, along with the project page that accompanied the paper submission.
Working with me on this project are:
Graduate Students:
-Vinicius Goecks, Ph.D. AERO
-Ritwik Bera, Ph.D. AERO
Acknowledgments
Research was sponsored by the U.S. Army Research Laboratory and was accomplished under Cooperative Agreement Number W911NF-18-2-0134. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the Army Research Laboratory or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for Government purposes not withstanding any copyright notation herein.