NASA Langley Research Center
1 September 2002 – 31 August 2007
Co-P.I.s John L. Junkins, Dimitris Lagoudas, Othon K. Rediniotis, John D. Whitcomb, and James Boyd
Total award $15,760,418
 NASA has chosen Texas A&M University to lead the Texas Institute of Intelligent Bio-Nano Materials and Structures for Aerospace Vehicles (TiiMS), bringing together some of the top researchers in Texas and the world — including a Nobel laureate and several members of the National Academies — in biotechnology, nanotechnology, biomaterials and aerospace engineering to develop the next generation of bio-nano materials and structures for aerospace vehicles. The technical scope for the institute focuses on basic research issues underlying the major theme of TiiMS — the marriage of biotechnology with nanotechnology to enable the development of intelligent reconfigurable aerospace structures.
NASA has chosen Texas A&M University to lead the Texas Institute of Intelligent Bio-Nano Materials and Structures for Aerospace Vehicles (TiiMS), bringing together some of the top researchers in Texas and the world — including a Nobel laureate and several members of the National Academies — in biotechnology, nanotechnology, biomaterials and aerospace engineering to develop the next generation of bio-nano materials and structures for aerospace vehicles. The technical scope for the institute focuses on basic research issues underlying the major theme of TiiMS — the marriage of biotechnology with nanotechnology to enable the development of intelligent reconfigurable aerospace structures.
The main focus of TiiMS is to develop and advance the nano and biotechnologies that enable our vision of adaptive, intelligent, shape-controllable micro and macro structures, for advanced aircraft and space systems. The key is integrating intelligence and multifunctionality into the varied components of aerospace systems and vehicles. Our research seeks to investigate and develop advanced control systems to enable intelligence, agility and adaptability of aerospace vehicles made from these smart materials.
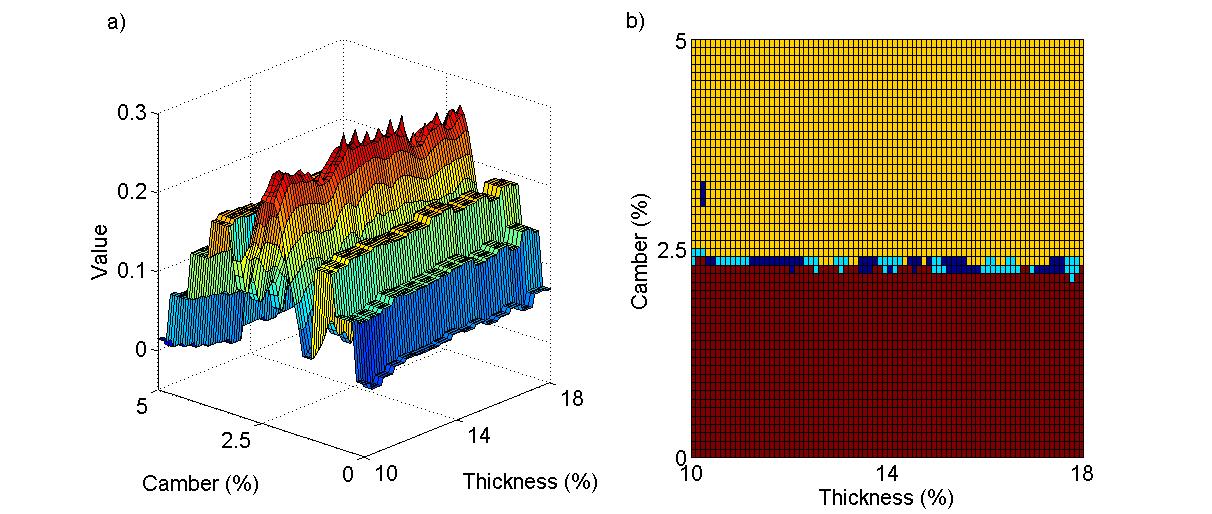
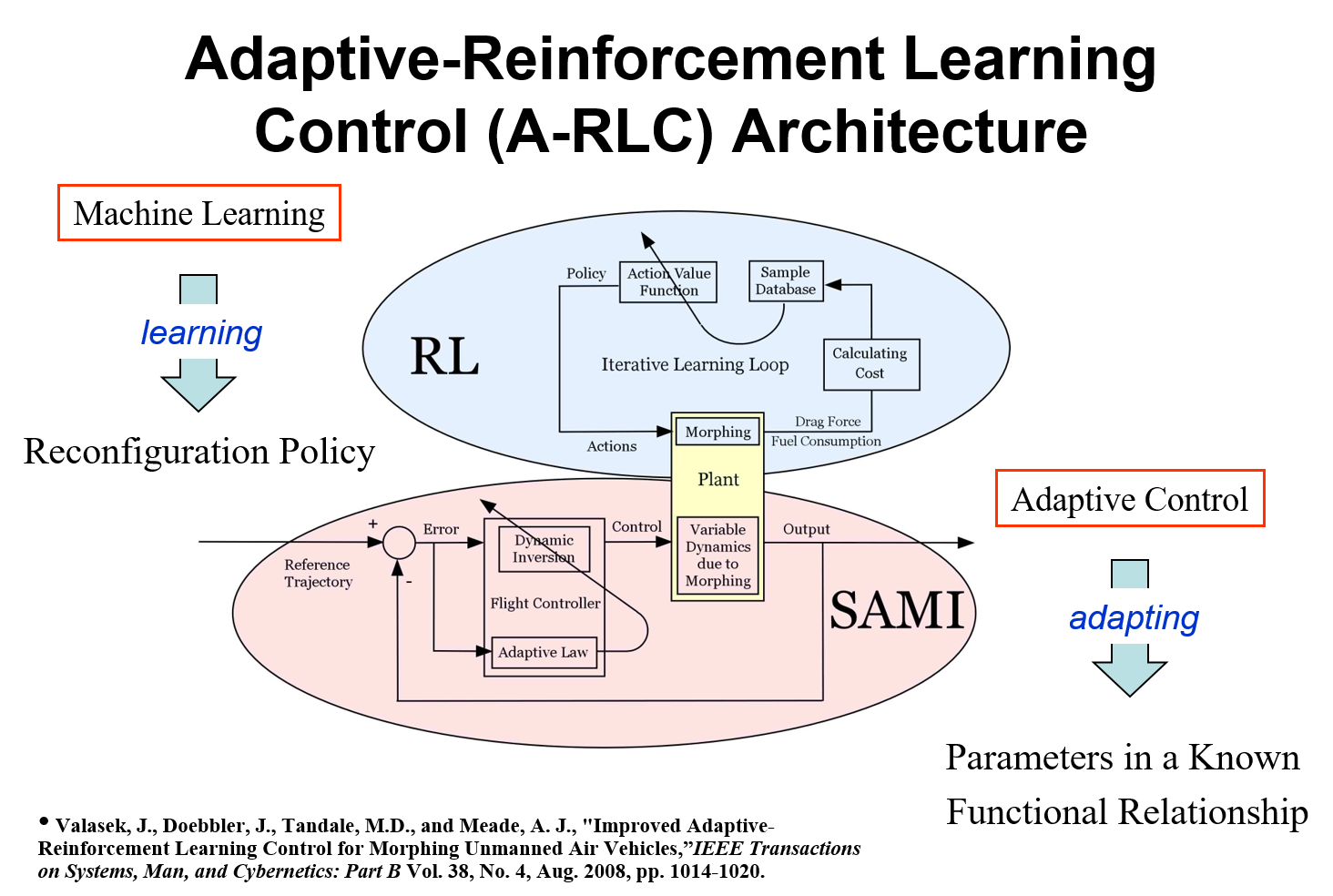 Research Objective 1: Characterization of Shape Memory Alloys using an Artificial Intelligence approach. The capability to control shape modifications of Shape Memory Alloy materials benefits from accurate models of the voltage/current-force/deformation relationships. These models are typically developed from a constitutive relation for the Shape Memory Alloy behavior which is then integrating into a structural model. The characterization approach used here does not need a constitutive model, but uses Reinforcement Learning to directly learn an input-output mapping characterization from physical experimentation, in real-time. This has the potential to significantly simplify and speed up the characterization process. Adaptive-Reinforcement Learning Control (A-RLC), a computational method that we created and developed, is being used to bridge the gap from numerical simulation to physical experimentation. We have designed and built a bench-test rig to validate the approach, and besides characterization, an optimal control policy is determined that learns how to control the shape of a Shape Memory Alloy to a specified length.
Research Objective 1: Characterization of Shape Memory Alloys using an Artificial Intelligence approach. The capability to control shape modifications of Shape Memory Alloy materials benefits from accurate models of the voltage/current-force/deformation relationships. These models are typically developed from a constitutive relation for the Shape Memory Alloy behavior which is then integrating into a structural model. The characterization approach used here does not need a constitutive model, but uses Reinforcement Learning to directly learn an input-output mapping characterization from physical experimentation, in real-time. This has the potential to significantly simplify and speed up the characterization process. Adaptive-Reinforcement Learning Control (A-RLC), a computational method that we created and developed, is being used to bridge the gap from numerical simulation to physical experimentation. We have designed and built a bench-test rig to validate the approach, and besides characterization, an optimal control policy is determined that learns how to control the shape of a Shape Memory Alloy to a specified length.
The results of this Objective are expected to aid in characterizing the effectiveness of this type of advanced control mechanism in intelligent systems, and further research in the modeling and control of morphing air and space vehicles.
Objective 1 goals:
- Determine the length of time that is required for the A-RLC unit to learn the nonlinear model of the actual material that will be employed in a morphing wing.
- Determine the A-RLC unit’s ability to optimize state-value functions and minimize a cost function of trajectories after having already learned the SMA model while not having had experience of the particular set of states required.
- Compare the A-RLC unit’s deduction of SMA behavior with current mathematical models of SMA behavior.
- Generate data that will allow future modification of the A-RLC unit to more quickly optimize the behavior of SMA actuators.
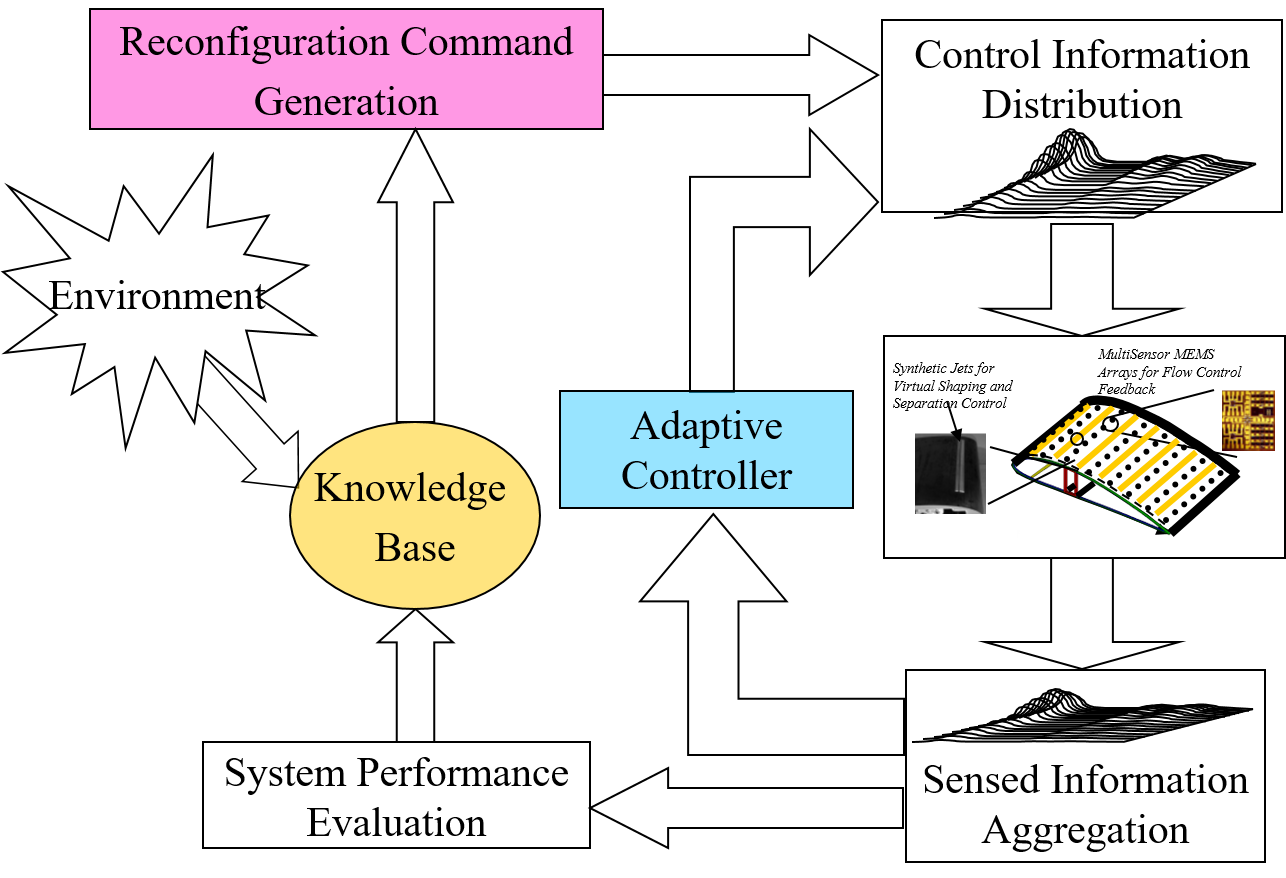 Research Objective 2: Intelligent shape changing control of morphing air vehicles that use distributed actuation and sensing on a massive scale. The Defense Advanced Research Projects Agency (DARPA) uses the definition of an air vehicle that is able to change its state substantially (to the order of 50% more wing area or wing span and chord) to adapt to changing mission environments, thereby providing superior system capability that is not possible without reconfiguration. We are developing an Adaptive-Reinforcement Learning Control (A-RLC) methodology to the problem of Morphing for Mission Adaptation. A-RLC is a marriage of traditional feedback control and Artifcial Intelligence intended to address two of the three essential functionalities for a morphing vehicle: how to reconfigure, and learning to reconfigure. The third is knowing when to reconfigure. A-RLC uses Structured Adaptive Model Inversion (SAMI) as the controller for tracking trajectories and handling time-varying properties, parametric uncertainties, un-modeled dynamics, and disturbances. Reinforcement Learning with a Q-Learning algorithm is used to learn how to produce the optimal shape at every flight condition over the life of the aircraft. Important aspects of nonlinear, massively distributed actuation and sensing systems are control effector saturation and stability. We are developing a rigorous theoretical framework that addresses these aspects. The A-RLC methodology will be demonstrated with a numerical simultation example of 3-D delta wing unmanned air vehicle that can morph in all three spatial dimensions, over a set of optimal shapes corresponding to specified flight conditions, while tracking a specified trajectory in the presence of disturbances.
Research Objective 2: Intelligent shape changing control of morphing air vehicles that use distributed actuation and sensing on a massive scale. The Defense Advanced Research Projects Agency (DARPA) uses the definition of an air vehicle that is able to change its state substantially (to the order of 50% more wing area or wing span and chord) to adapt to changing mission environments, thereby providing superior system capability that is not possible without reconfiguration. We are developing an Adaptive-Reinforcement Learning Control (A-RLC) methodology to the problem of Morphing for Mission Adaptation. A-RLC is a marriage of traditional feedback control and Artifcial Intelligence intended to address two of the three essential functionalities for a morphing vehicle: how to reconfigure, and learning to reconfigure. The third is knowing when to reconfigure. A-RLC uses Structured Adaptive Model Inversion (SAMI) as the controller for tracking trajectories and handling time-varying properties, parametric uncertainties, un-modeled dynamics, and disturbances. Reinforcement Learning with a Q-Learning algorithm is used to learn how to produce the optimal shape at every flight condition over the life of the aircraft. Important aspects of nonlinear, massively distributed actuation and sensing systems are control effector saturation and stability. We are developing a rigorous theoretical framework that addresses these aspects. The A-RLC methodology will be demonstrated with a numerical simultation example of 3-D delta wing unmanned air vehicle that can morph in all three spatial dimensions, over a set of optimal shapes corresponding to specified flight conditions, while tracking a specified trajectory in the presence of disturbances.
Objective 2 goals:
- Modeling and control of hierarchical adaptive systems.
- Distributed sensing, actuation and intelligence.
- Applications at different length scales.
Research Objective 3: Space Based Radar (SBR) antenna reconfiguration by morphing. The state of the art in spacecraft communication requires that multiple antennas be mounted on a single spacecraft so as to permit communication with multiple ground stations, many of which have unique receivers and transmitter characteristics. Our approach is to use a single antenna capable of altering its geometry to achieve world-wide compatibility between receivers and transmitters. We seek to develop and demonstrate the feasibility of a reconfigurable antenna shape controller that can achieve and control the optimal antenna shape, on demand. Shape-Memory Alloys (SMA) have been employed to enhance structural properties and increase the ability of structures to adapt and conform as desired, and antenna elements rigged with SMA actuators will be used here as the actuation element. Adaptive-Reinforcement Learning Control A-RLC) will be used to efficiently alter the antenna shape to achieve optimal concavity. This controller is capable of independently learning the optimal concavity in a lifelong sense, thus allowing a space-based radar and communication systems to decrease the quantity of antennas currently mounted on spacecraft.
Objective 3 goals:
- Synthesize an original Reinforcement Learning algorithm.
- Construct a simple finite element model of a parabolic antenna element.
- Quantify input/output behavior of a space antenna utilizing SMA actuators.
- Demonstrate reconfiguration capability using simulation.
Working with me on this program are Graduate Research Assistants:
- Monish Tandale
- Jie Rong
- Paul Gesting
- James Doebbler
- Theresa Spaeth
and Undergraduate Research Assistants:
- Chris Haag
- Holly Feldman